DE Analysis with Exact Tests
Overview
Teaching: 30 min
Exercises: 30 minQuestions
How do I need to prepare my data for analysis in R?
What standard statistical methods do I need to analyze this data set?
What packages are available to me for biostatistical data analysis in R?
How do I perform basic differential gene expression analysis using R packages?
Objectives
Become familiar with standard statistical methods in R for quantifying transcriptomic gene expression data.
Gain hands-on experience and develop skills to be able to use R to visualize and investigate patterns in omics data.
Be able to install and load the necessary biostatistics R packages.
Be able to run functions from biostatistics packages for data analysis and visualization in R.
Statistical Analysis in R - Exact Tests
With our transcript sequence data now aligned and quantified, we can begin to perform some statistical analysis of the data. For next generation squencing data (e.g., RNA sequences), it is a common task to identify differentially expressed genes (tags) between two (or more) groups. Exact tests often are a good place to start with differential expression analysis of transcriptomic data sets. These tests are the classic edgeR approach to make pairwise comparisons between the groups.
Once negative binomial models are fitted and dispersion estimates are obtained, we can proceed with testing procedures for determining differential expression of the genes in our Tribolium castaneum reference genmoe using the exactTest function of edgeR.
Note: the exact test in edgeR is based on the qCML methods. By knowing the conditional distribution for the sum of counts in a group, we can compute exact p-values by summing over all sums of counts that have a probability less than the probability under the null hypothesis of the observed sum of counts.
Tip!
The exact test for the negative binomial distribution has strong parallels with Fisher’s exact test, and is only applicable to experiments with a single factor. The Fisher’s exact test is used to determine if there is a significant association between two categorical variables. And it is typically used as an alternative to the Chi-Square Test of Independence when the data is small.
So, the types of contrasts you can make will depend on the design of your study and data set. The experimental design of the data we are using in this workshop is as follows:
| sample | treatment | hours |
|---|---|---|
| SRR8288561 | cntrl | 4h |
| SRR8288562 | cntrl | 4h |
| SRR8288563 | cntrl | 4h |
| SRR8288564 | treat | 4h |
| SRR8288557 | treat | 4h |
| SRR8288560 | treat | 4h |
| SRR8288558 | cntrl | 24h |
| SRR8288567 | cntrl | 24h |
| SRR8288568 | cntrl | 24h |
| SRR8288559 | treat | 24h |
| SRR8288565 | treat | 24h |
| SRR8288566 | treat | 24h |
Note in the treatment column:
- cntrl - control treatment
- treat - treatment of UV-B exposure
It is apparent from the above experimental design layout that we are at least able to perform exact tests (t-tests) with the read count (gene expression) data.
After normalization of raw counts we will perform genewise exact tests for differences in the means between two groups of gene counts. Specifically, the two experimental groups of treatment and control for the Tribolium castaneum transcript sequence data.
Software Prerequisites
Note: be sure that you have loaded the edgeR R library before we proceed with the bioinformatics analysis workflow.
Further information and tips for installing the edgeR R library may be found on the Setup page.
We will use the edgeR library in R with the data frame of transcript sequence read counts from the previous step of the bioinformatics workflow.
Tip!
Remember to load the edgeR library before you attempt to use the following functions.
library("edgeR")
Before we proceed with conducting any analysis in R, we should set our working directory to the location of our data. Then, we need to import our data using the read.csv function.
# set the working directory
setwd("/YOUR/FILE/PATH/")
# import gene count data
tribolium_counts <- read.csv("TriboliumCounts.csv", row.names="X")
As a first step in the analysis, we need to describe the layout of samples in our transcript sequence read count data frame using a list object.
# add grouping factor to specify the layout of the count data frame
group <- factor(c(rep("cntrl_4h",3), rep("treat_4h",3), rep("cntrl_24h",3), rep("treat_24h",3)))
# create DGE list object
list <- DGEList(counts=tribolium_counts,group=group)
This is a good point to generate some interesting plots of our input data set before we begin preparing the raw gene counts for the exact test.
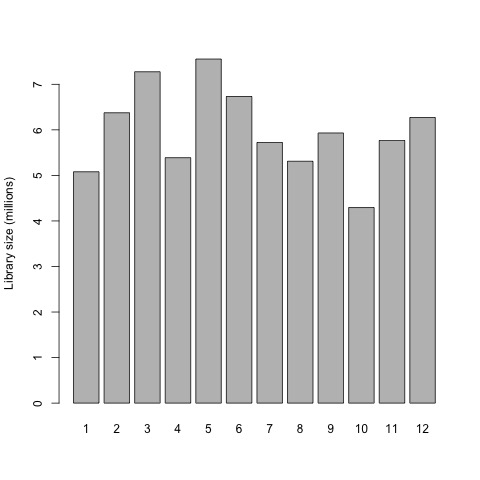
So first, we will now plot the library sizes of our sequencing reads before normalization using the barplot function.
# plot the library sizes before normalization
barplot(list$samples$lib.size*1e-6, names=1:12, ylab="Library size (millions)")
Plot
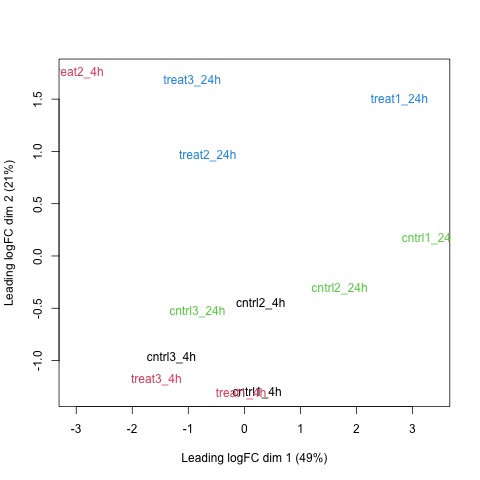
Next, we will use the plotMDS function to display the relative similarities of the samples and view batch and treatment effects before normalization.
# draw a MDS plot to show the relative similarities of the samples
# and to view batch and treatment effects before normalization
plotMDS(list, col=rep(1:12, each=3))
Plot
There is no purpose in analyzing genes that are not expressed in either experimental condition (treatment or control), so raw gene counts are first filtered by expression levels.
# gene expression is first filtered based on expression levels
keep <- filterByExpr(list)
table(keep)
list <- list[keep, , keep.lib.sizes=FALSE]
# calculate normalized factors
list <- calcNormFactors(list)
normList <- cpm(list, normalized.lib.sizes=TRUE)
#Write the normalized counts to a file
write.table(normList, file="tribolium_normalizedCounts.csv", sep=",", row.names=TRUE)
# view normalization factors
list$samples
dim(list)
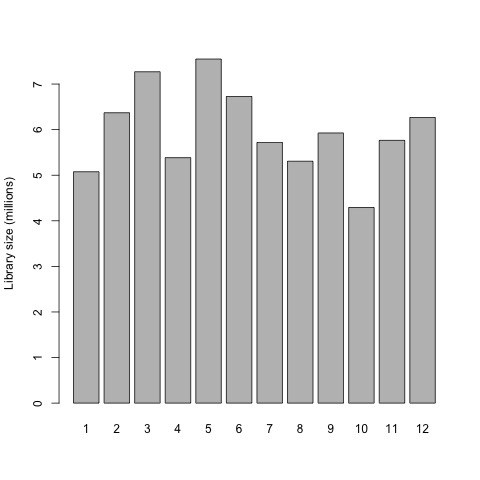
Now that we have normalized gene counts for our samples we should generate the same set of previous plots for comparison.
# plot the library sizes after normalization
barplot(list$samples$lib.size*1e-6, names=1:12, ylab="Library size (millions)")
# draw a MDS plot to show the relative similarities of the samples
# and to view batch and treatment effects after normalization
plotMDS(list, col=rep(1:12, each=3))
Plots
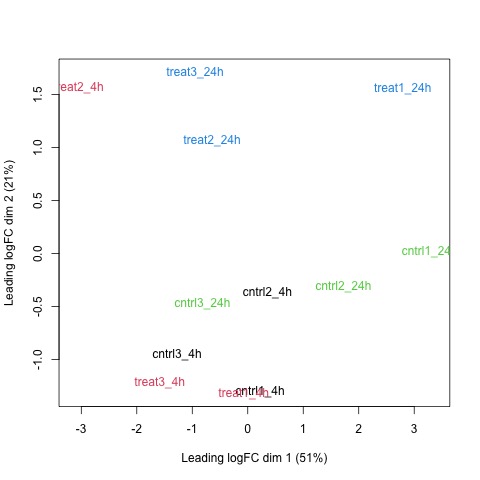
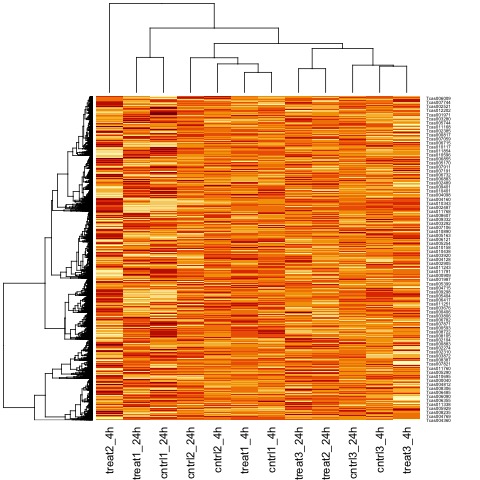
It can also be useful to view the moderated log-counts-per-million after normalization using the cpm function results with heatmap.
# draw a heatmap of individual RNA-seq samples using moderated
# log-counts-per-million after normalization
logcpm <- cpm(list, log=TRUE)
heatmap(logcpm)
Plot
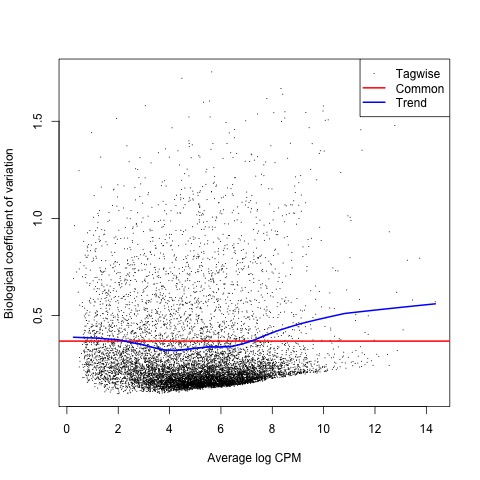
With the normalized gene counts we can also produce a matrix of pseudo-counts to estimate the common and tagwise dispersions. This allows us to use the plotBCV function to generate a genewise biological coefficient of variation (BCV) plot of dispersion estimates.
# produce a matrix of pseudo-counts and
# estimate common dispersion and tagwise dispersions
list <- estimateDisp(list)
list$common.dispersion
# view dispersion estimates and biological coefficient of variation
plotBCV(list)
Plot
Exact Tests - treat_4h vs ctrl_4h
Now, we are ready to perform exact tests with edgeR using the exactTest function.
#Perform an exact test for treat_4h vs ctrl_4h
tested <- exactTest(list, pair=c("cntrl_4h", "treat_4h"))
#Create results table of DE genes
resultsTbl <- topTags(tested, n=nrow(tested$table))$table
#Create filtered results table of DE genes
resultsTbl.keep <- resultsTbl$FDR <= 0.05
resultsTblFiltered <- resultsTbl[resultsTbl.keep,]
Using the resulting differentially expressed (DE) genes from the exact test we can view the counts per million for the top genes of each sample.
# look at the counts-per-million in individual samples for the top genes
o <- order(tested$table$PValue)
cpm(list)[o[1:10],]
# view the total number of differentially expressed genes at a p-value of 0.05
summary(decideTests(tested))
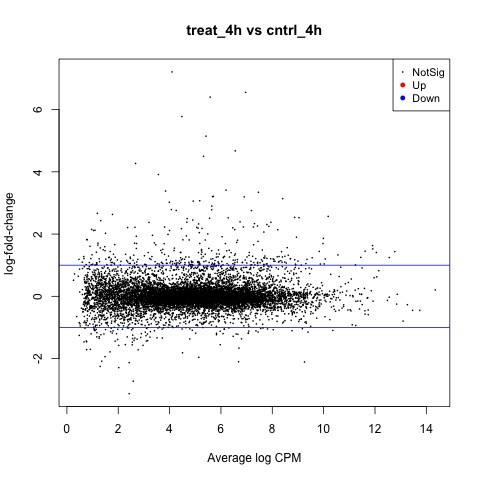
We can also generate a mean difference (MD) plot of the log fold change (logFC) against the log counts per million (logcpm) using the plotMD function. DE genes are highlighted and the blue lines indicate 2-fold changes.
# plot log-fold change against log-counts per million, with DE genes highlighted
# the blue lines indicate 2-fold changes
plotMD(tested)
abline(h=c(-1, 1), col="blue")
Plot
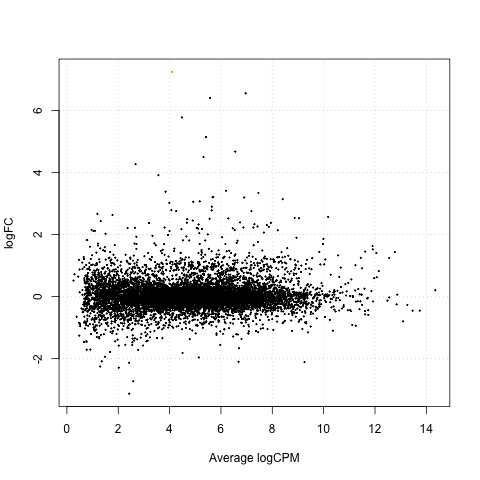
As a final step, we will produce a MA plot of the libraries of count data using the plotSmear function. There are smearing points with very low counts, particularly those counts that are zero for one of the columns.
# make a mean-difference plot of the libraries of count data
plotSmear(tested)
Plot
Exact Tests - treat_24h vs ctrl_24h
Next, we will perform exact tests on the 24h data with edgeR using the exactTest function.
#Perform an exact test for treat_24h vs ctrl_24h
tested_24h <- exactTest(list, pair=c("cntrl_24h", "treat_24h"))
#Create a table of DE genes filtered by FDR
resultsTbl_24h <- topTags(tested_24h, n=nrow(tested_24h$table))$table
#Create filtered results table of DE genes
resultsTbl_24h.keep <- resultsTbl_24h$FDR <= 0.05
resultsTbl_24h_filtered <- resultsTbl_24h[resultsTbl_24h.keep,]
#Write the results of the exact tests to a csv file
write.table(resultsTbl_24h_filtered, file="exactTest_24h_filtered.csv", sep=",", row.names=TRUE)
Using the resulting differentially expressed (DE) genes from the exact test we can view the counts per million for the top genes of each sample.
#Look at the counts-per-million in individual samples for the top genes
o <- order(tested_24h$table$PValue)
cpm(list)[o[1:10],]
# view the total number of differentially expressed genes at a p-value of 0.05
summary(decideTests(tested_24h))
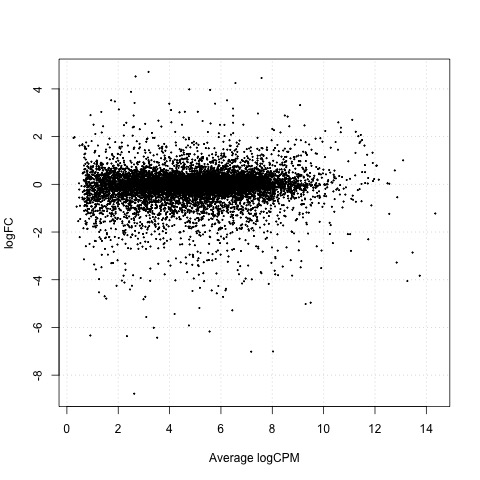
We can also generate a mean difference (MD) plot of the log fold change (logFC) against the log counts per million (logcpm) using the plotMD function. DE genes are highlighted and the blue lines indicate 2-fold changes.
# plot log-fold change against log-counts per million, with DE genes highlighted
# the blue lines indicate 2-fold changes
plotMD(tested_24h)
abline(h=c(-1, 1), col="blue")
Plot
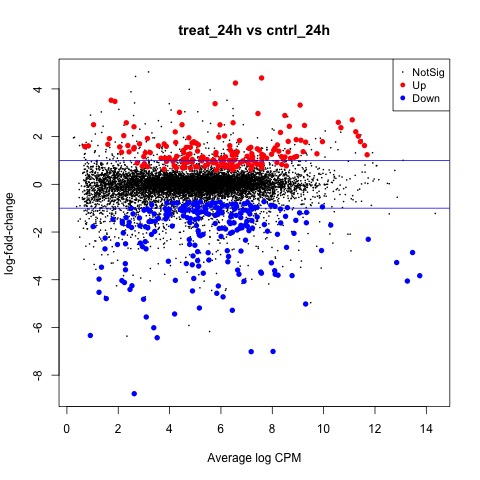
As a final step, we will produce a MA plot of the libraries of count data using the plotSmear function. There are smearing points with very low counts, particularly those counts that are zero for one of the columns.
# make a mean-difference plot of the libraries of count data
plotSmear(tested_24h)
Plot
Exact Tests - treat_4h vs treat_24h
Next, we will perform exact tests on the treatment data with edgeR using the exactTest function.
#Perform an exact test for treat_4h vs treat_24h
tested_treat <- exactTest(list, pair=c("treat_24h", "treat_4h"))
#Create a table of DE genes filtered by FDR
resultsTbl_treat <- topTags(tested_treat, n=nrow(tested_treat$table))$table
#Create filtered results table of DE genes
resultsTbl_treat.keep <- resultsTbl_treat$FDR <= 0.05
resultsTbl_treat_filtered <- resultsTbl_treat[resultsTbl_treat.keep,]
#Write the results of the exact tests to a csv file
write.table(resultsTbl_treat_filtered, file="exactTest_treat_filtered.csv", sep=",", row.names=TRUE)
Using the resulting differentially expressed (DE) genes from the exact test we can view the counts per million for the top genes of each sample.
#Look at the counts-per-million in individual samples for the top genes
o <- order(tested_treat$table$PValue)
cpm(list)[o[1:10],]
# view the total number of differentially expressed genes at a p-value of 0.05
summary(decideTests(tested_treat))
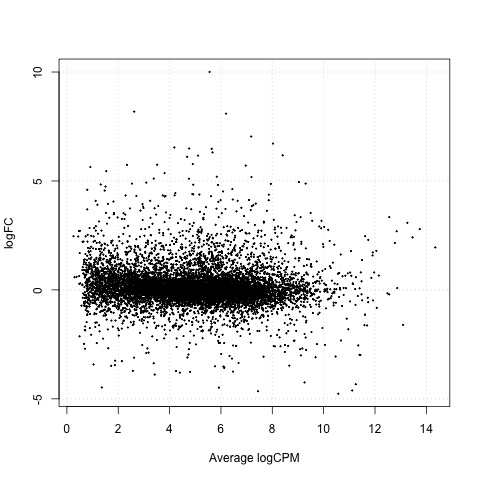
We can also generate a mean difference (MD) plot of the log fold change (logFC) against the log counts per million (logcpm) using the plotMD function. DE genes are highlighted and the blue lines indicate 2-fold changes.
# plot log-fold change against log-counts per million, with DE genes highlighted
# the blue lines indicate 2-fold changes
plotMD(tested_treat)
abline(h=c(-1, 1), col="blue")
Plot
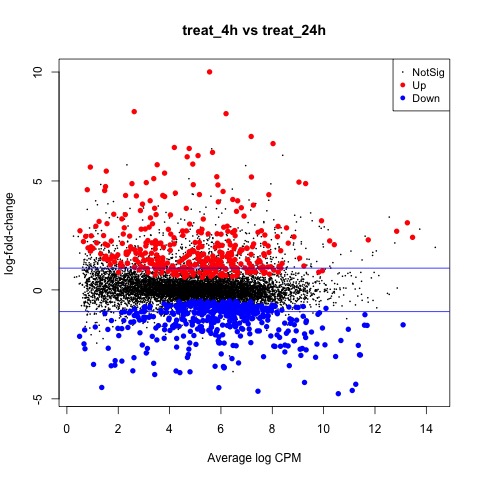
As a final step, we will produce a MA plot of the libraries of count data using the plotSmear function. There are smearing points with very low counts, particularly those counts that are zero for one of the columns.
# make a mean-difference plot of the libraries of count data
plotSmear(tested_treat)
Plot
Exact Tests - cntrl_4h vs cntrl_24h
Next, we will perform exact tests on the control data with edgeR using the exactTest function.
#Perform an exact test for cntrl_4h vs ctrl_24h
tested_cntrl <- exactTest(list, pair=c("cntrl_24h", "cntrl_4h"))
#Create a table of DE genes filtered by FDR
resultsTbl_nctrl <- topTags(tested_cntrl, n=nrow(tested_cntrl$table))$table
#Create filtered results table of DE genes
resultsTbl_nctrl.keep <- resultsTbl_nctrl$FDR <= 0.05
resultsTbl_treat_filtered <- resultsTbl_nctrl[resultsTbl_nctrl.keep,]
#Write the results of the exact tests to a csv file
write.table(resultsTbl_cntrl_filtered, file="exactTest_cntrl_filtered.csv", sep=",", row.names=TRUE)
Using the resulting differentially expressed (DE) genes from the exact test we can view the counts per million for the top genes of each sample.
#Look at the counts-per-million in individual samples for the top genes
o <- order(tested_cntrl$table$PValue)
cpm(list)[o[1:10],]
# view the total number of differentially expressed genes at a p-value of 0.05
summary(decideTests(tested_cntrl))
We can also generate a mean difference (MD) plot of the log fold change (logFC) against the log counts per million (logcpm) using the plotMD function. DE genes are highlighted and the blue lines indicate 2-fold changes.
# plot log-fold change against log-counts per million, with DE genes highlighted
# the blue lines indicate 2-fold changes
plotMD(tested_cntrl)
abline(h=c(-1, 1), col="blue")
Plot
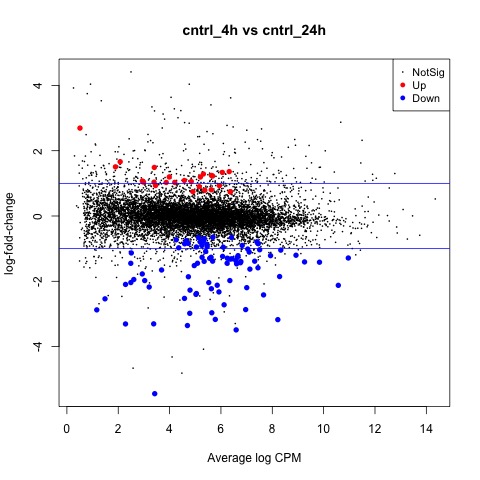
As a final step, we will produce a MA plot of the libraries of count data using the plotSmear function. There are smearing points with very low counts, particularly those counts that are zero for one of the columns.
# make a mean-difference plot of the libraries of count data
plotSmear(tested_cntrl)
Plot
Scripts for this Lesson
Here is the R script with the code from this lesson. Also included is a R script with the plots being written to jpg files, rather than output to the screen.
Key Points
The BiocManager is is a great tool for installing Bioconductor packages in R.
Make sure to use the ? symbol to check the documentation for most R functions.
Fragments of sequences from RNA sequencing may be mapped to a reference genome and quantified.
The edgeR manual has many good examples of differential expression analysis on different data sets.